🔥 High-fidelity reconstruction with only 8K vertices (vs 80K Gaussian points).
🔥 One-shot animatable mesh generation in a single forward pass.
🔥 Fast reconstruction within a second.
We introduce MeshLAM, a feed-forward framework for one-shot animatable mesh head reconstruction that generates high-fidelity, animatable 3D head avatars from a single image. Unlike previous work that relies on time-consuming test-time optimization or extensive multi-view data, our method produces complete mesh representations with inherent animatability from a single image in a single forward pass.
Our approach employs a dual shape and texture map architecture that simultaneously processes mesh vertices and texture map with extracted image features from a shared transformer backbone, allowing for coherent shape carving and appearance modeling. To prevent mesh collapse and ensure topological integrity during feed-forward deformation, we propose an iterative GRU-based decoding mechanism with progressive geometry deformation and texture refinement, coupled with a novel reprojection-based texture guidance mechanism that anchors appearance learning to the input image.
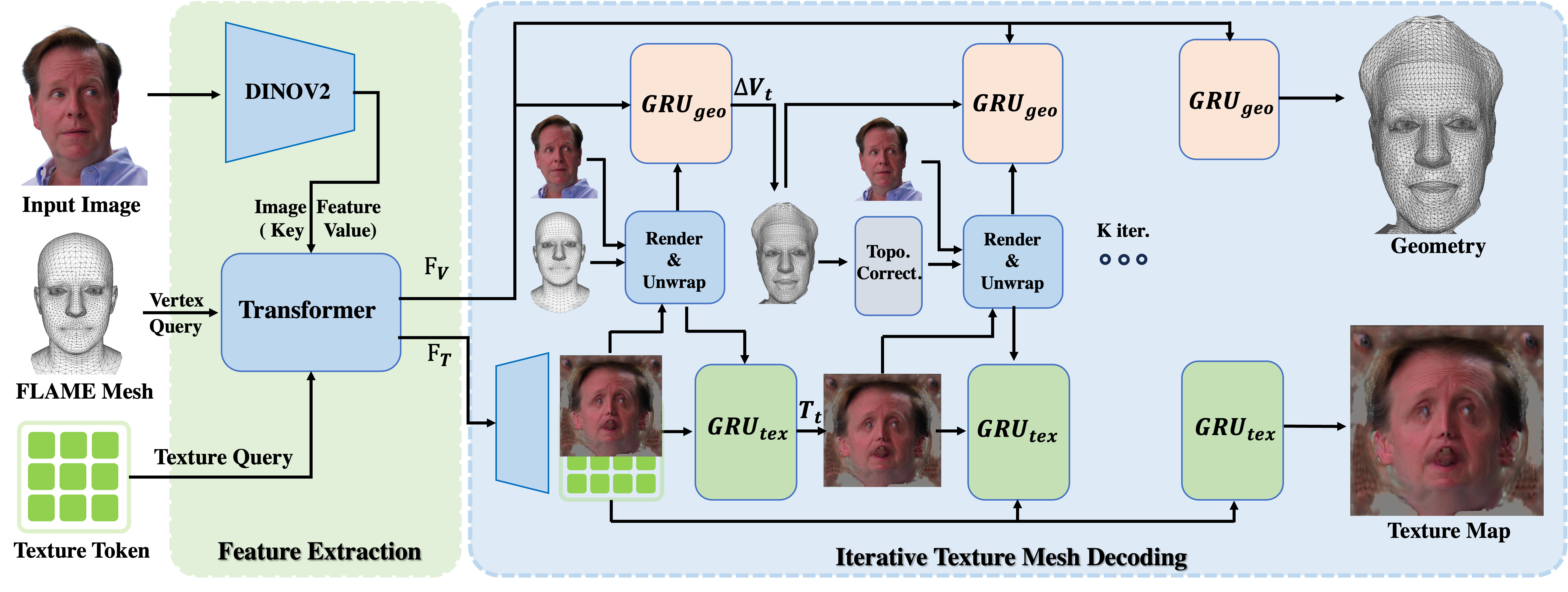
Figure 1: Overall Framework. Our method reconstructs an animatable 3D texture head mesh from a single image through dual shape and texture branches. Both branches are refined iteratively via GRU decoders with topology correction and reprojection guidance.
We build upon the FLAME model as a parametric prior for identity, expression, and topology. Our dual-branch architecture explicitly decouples shape and appearance learning: one branch predicts per-vertex deformations relative to a FLAME template to capture geometric details, while the other synthesizes a high-resolution UV-aligned texture map for photorealistic surface appearance.
Separate vertex deformations and UV texture maps enable efficient shape modeling with sparse vertices while preserving high-fidelity appearance in a compact texture map.
Progressive mesh deformation and texture refinement through GRU decoders effectively alleviates mesh collapse and maintains topological coherence.
Unwraps input image and prediction error onto the deformed mesh, providing direct visual supervision for realistic texture generation.

Figure 2: Qualitative comparison on challenging texture cases. Our method captures fine details (tattoos, facial features) that NeRF- and Gaussian-based methods fail to reconstruct with a single forward pass.

Figure 3: Our mesh-based framework successfully models geometry and high-fidelity texture details (tattoos, text, hair strands) with only 8K vertices, substantially outperforming Gaussian-based methods requiring 80K points.

Figure 4: Reconstruction results on extreme cases and diverse scenarios. Our method robustly handles challenging cases including occlusion and various lighting conditions.

Figure 5: Cross-domain generalization enables text-to-3D avatar generation (top) and avatar style transfer/editing (bottom). Our framework seamlessly integrates with pretrained text-to-image and image editing models, producing animatable 3D avatars in a single forward pass.
Our framework naturally extends to text-conditioned 3D avatar generation. By leveraging pretrained text-to-image models, we generate a complete 3D avatar from text prompts with coherent geometry and texture.
Unlike previous 3D editing frameworks requiring per-style training, our approach enables efficient avatar style transfer in a single forward pass. The resulting avatars maintain artistic style while remaining fully animatable.
@misc{he2026meshlamfeedforwardoneshotanimatable,
title={MeshLAM: Feed-Forward One-Shot Animatable Textured Mesh Avatar Reconstruction},
author={Yisheng He and Steven Hoi},
year={2026},
eprint={2604.22865},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2604.22865},
}